スマートグラス「MOVERIO」で、視界の拡張を試してみます。
別アングルの映像を、同時に見られるようにしてみましょう。
現実と俯瞰映像を同時に見るテスト
私が今回テストしたのは、ボールを投げながら、俯瞰映像で上からボールの位置を同時に見るというものです。
ちなみに、白いボールに近づける「ボッチャ」というスポーツを、テスト題材としています。
ボッチャは俯瞰映像じゃないとボールの距離が分からないので試してみました。ちょっとサンプルとしてはマニアックかも。
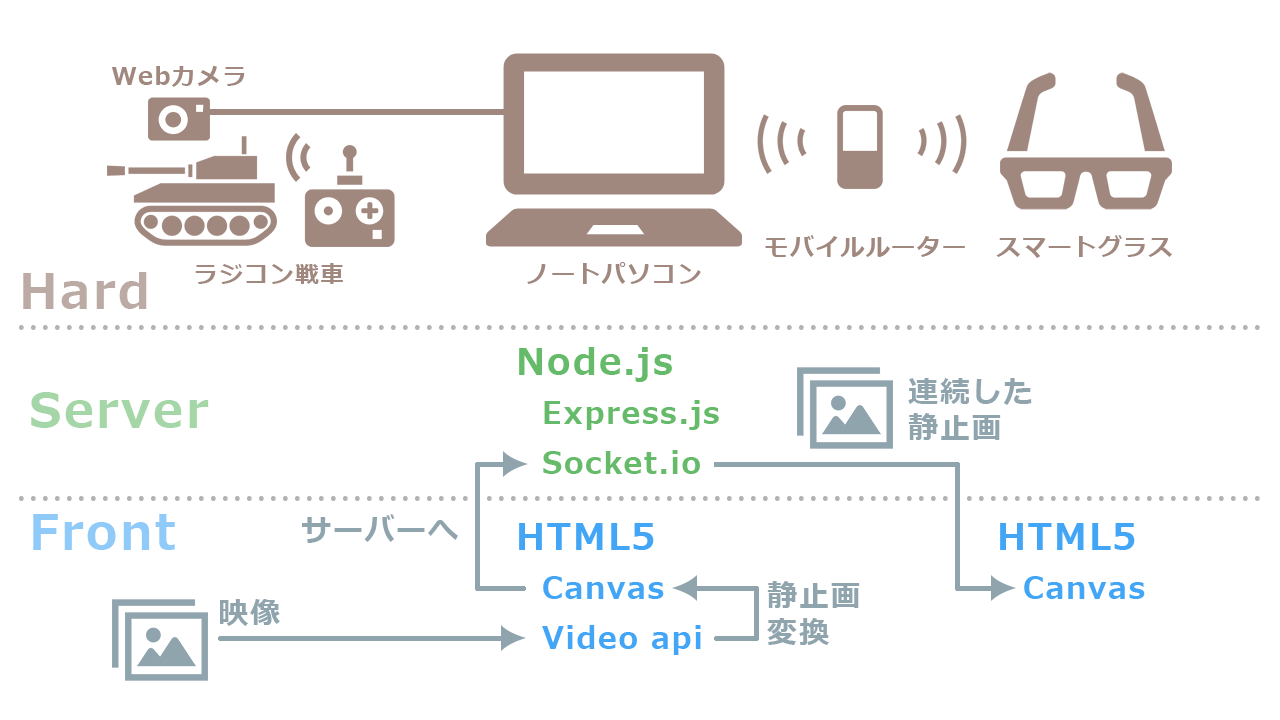
ハード構成
Windowsノートパソコン・・・CORE i7
Webカメラ・・・LOGICOOL C270
スマートグラス・・・MOVERIO BT-300
システム構成
今回のテスト内容だけならWebRTCを使うのが良いような気がします。
しかし、下記のような構成をすでに構築したことがあるので流用しています。
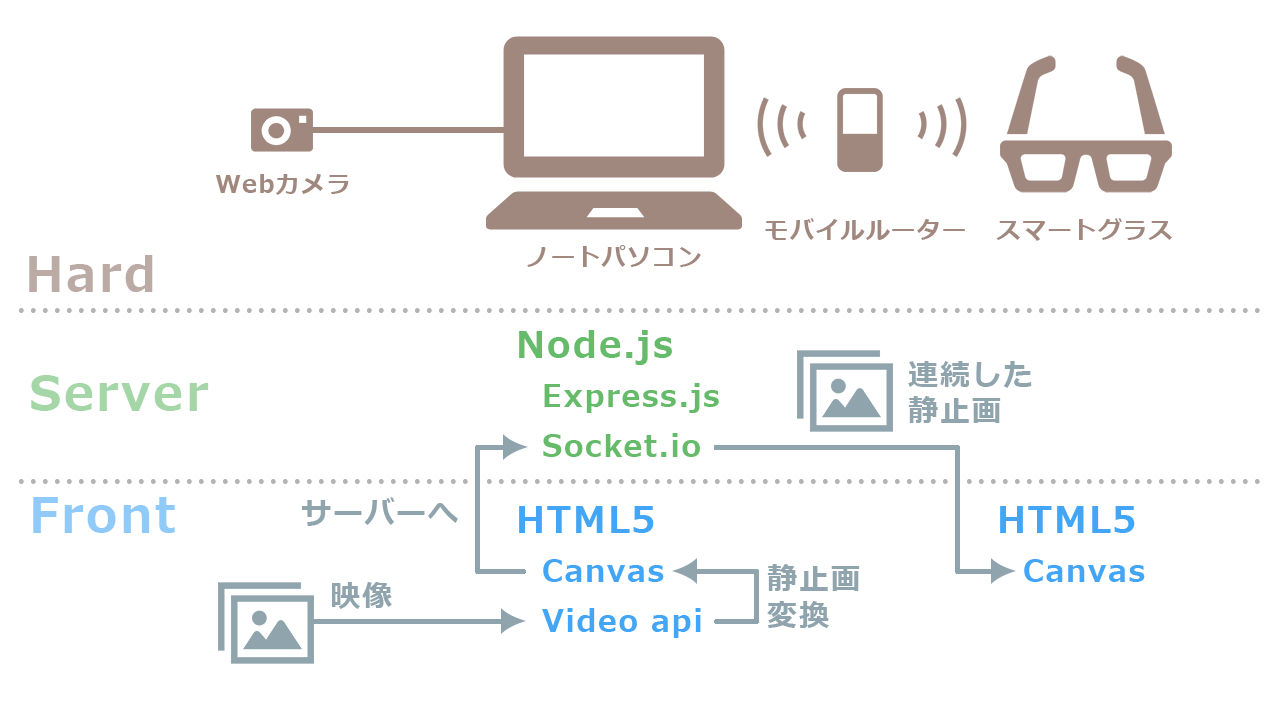
ノートパソコンをサーバーにして、Webカメラの映像をスマートグラスに飛ばします。HTMLとCSSとJSだけのWeb技術者にとってハードルの低い構成です。
ディレクトリ構成は以下になります。
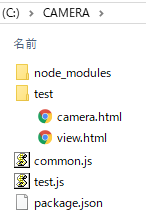
test.jsにサーバープログラムが書かれています。
一部、他でも共用しそうなプログラムを、common.jsに切り分けています。
testフォルダ内にあるHTMLがカメラ映像の入出力をするWebアプリです。
node_modulesフォルダと、package.jsonは、Node.js関係のもの。説明は省略。
サーバー側プログラム
まずはサーバー側のコードを掲載します。Node.js、Express、Socket.ioのインストールは情報も多いので割愛します。
環境
Windows10
Node.js 6.11.0
Express 4.15.3
サーバー本体 test.jsのコード
var TCP_PORT = 3000,
DIRECTORY = 'test',
express = require('express'),
app = express(),
http = require('http').Server(app),
io = require('socket.io')(http);
var COMMON = require('./common.js');
var init = function () {
app.use(express.static(DIRECTORY));
http.listen(TCP_PORT, function(){
console.log(COMMON.getIP() + ':' + TCP_PORT + ' でサーバーを起動');
});
setIo();
},
//ソケットIO設定
setIo = function(){
io.on('connection',function(socket){
socket.on('camera',function(data){
io.emit('dataURL',data);
});
});
};
init();
サーバーを立ち上げて、Socket.ioで画像のdateURLを送受信する仕組みです。
8行目で読み込んでいるcommon.jsのコードは以下です。
//ローカルIPアドレス取得
exports.getIP = function(){
var os = require('os'),
ip,
interfaces = os.networkInterfaces();
var getIPv4 = function(){
interfaces[dev].forEach(function(details){
if (details.family === 'IPv4' && details.address.indexOf('192.') > -1){
ip = details.address;
}
});
};
for (var dev in interfaces) {
getIPv4(dev);
}
return ip;
};
自分の使っているローカルIPをアドレスを、コンソールログで表示させるだけのプログラムです。切り分けなくても良いですし、なくても良いです。
フロント側プログラム
続いてHTML5を使ったフロント側のコードを掲載します。
Webカメラの映像を取得してサーバーに送るcamera.html
<!doctype html>
<html>
<head>
<title>Camera</title>
<script src="/socket.io/socket.io.js"></script>
<style media="screen">
body {
background-color: #000;
text-align: center;
}
video {
display: none;
}
</style>
</head>
<body>
<video id="webCamera" width="640" height="480" autoplay></video>
<canvas id="canvas" width="320" height="240"></canvas>
<script type="text/javascript">
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia;
window.URL = window.URL || window.webkitURL;
var socket = io(),
video = document.getElementById('webCamera'),
canvas = document.getElementById('canvas'),
canvas_w = canvas.clientWidth,
canvas_h = canvas.clientHeight;
navigator.getUserMedia({video: true, audio: false},
function(stream){
console.log(stream);
video.src = window.URL.createObjectURL(stream);
video.addEventListener('timeupdate', webCameraTimeUpdate);
video.play();
},
function(err){
console.log(err);
}
);
function webCameraTimeUpdate(){
var ctx = canvas.getContext('2d');
ctx.drawImage(video,0,0,canvas_w,canvas_h);
var data = canvas.toDataURL();
socket.emit('camera', data);
}
</script>
</body>
</html>
640px幅でWebカメラから動画を取得して、320pxに縮小しています。
21行目、22行目は最新のChromeで動かすときは必要ありませんが、「MOVERIO」など、古いブラウザで動かしたいときは必要です。
サーバー映像(連続した静止画)を受信するview.html
<!doctype html>
<html>
<head>
<title>view</title>
<script src="/socket.io/socket.io.js"></script>
<style media="screen">
body {
background-color: #000;
text-align: center;
}
</style>
</head>
<body>
<img id="videoImg" alt="" width="640px" height="480px;">
<script>
var socket = io(),
videoImg = document.getElementById('videoImg');
socket.on("dataURL", function(data){
videoImg.setAttribute('src', data);
});
</script>
</body>
</html>
軽量化していた320px幅の画像を、640pxに戻しています。
サーバー起動とブラウザ立ち上げ
コマンドプロントを立ち上げ、サーバーのディレクトリ(私の場合はC:\CAMERA)に移動します。
を打ち込みEnter。サーバーが起動します。
そのあとブラウザでcamera.htmlを読み込みますが、現在のChrome60だとhttpsではない通信で、カメラをブラウザから起動できません。
http://192.168.X.X:3000/camera.html
というURLではだめなので、https環境を用意するか、
http://localhost:3000/camera.html
という、ローカルホストで読み込む必要があります。
テストであればローカルホストで十分です。

Webカメラの映像が、ブラウザに映し出されます。
正確にはWebカメラの映像を、HTML5のCanvasに転写したものが表示されています。若干カクカクしていると思います。
なお、カメラが複数あるときは、右上のカメラアイコンで、別のカメラを選択してください。
スマートグラスの準備

スマートグラス「MOVERIO」を着用し、ブラウザでview.htmlを開きます。
http://192.168.X.X:3000/view.html
IPアドレスは、コマンドプロントで表示されたものを入力。
目の前にカメラの映像が表示されると思います。
投球してみよう!
カメラを任意の場所へセットすれば準備は完了です。ボールを投げてみます。

・・・。
なんか、おもしろい。
そして不思議な体験です。
スマートグラスに映す必要性があるか問われると疑問ですが、近未来の感覚を体験できます。
ただ、「MOVERIO」は正面に映像が見えるタイプのスマートグラスなので、その映像を避けながら現実を見ないといけません。映像を小さくして、端っこに表示しても良いでしょう。
思ったより遅延しない
映像の遅延は0.86秒。映像の解像度を抑えているため、1秒以内に収まっています。通信環境によって遅延時間は変わると思います。
今回のような投球の映像であれば、リプレイを見ているような別のメリットがあるので、逆に遅れて良いような気がします。
映像はカクカクしているので、精密な映像を求めるときは、この構成では無理があるでしょう。
汎用性の高いWebアプリ
今回のようなブラウザで動くWebアプリは、汎用性が高いです。
デバイスに依存しません。(本当は依存しますが・・・)
ブラウザを搭載したスマートグラスであれば「MOVERIO」じゃなくても動作しますし、スマートグラスに限らず、iPhoneでもAndroidスマートフォンでも動作します。
視界の共有もできる
また、今回テストした構成とは逆で、スマートグラスとパソコンのHTMLを入れ替えて読み込むことで、スマートグラスのカメラの映像をパソコンに送ることができます。
スマートグラスをかけた人の視界を遠隔で共有できます。これはすでにフィールド業務(機械・システムの運転)で活用事例があります。
視界の拡張の利用場面
今回のサンプルの利用場面を考えてみます。
スポーツしながら別アングル映像を見るという使い方より、スポーツ観戦しながら利用する方が適しています。
選手の表情のアップや、自席から見えないアングルの映像を見られるとおもしろいです。
他にも、防犯で有効活用が期待できます。
監視カメラの映像を視界の隅に映し、ガードマンに着用させるのが良いかもしれません。
死角のない警備ができそうです。
また、赤ちゃんのうつ伏せ寝を監視も、できるかもしれません。
保育士の人手不足で、もうスマートグラスで視界を拡張しないと、子供を見切れないのでは?と、思うことはあります。
あとは、背面カメラ。
子供を連れて自転車で移動するときの、安全確保で利用できれば。
親が先頭を走って誘導すると、後ろをついてくる子供が見えません。
頻繁に後ろを振り向いて確認しますが、その間、前方を見ていないので危険です。
スマートグラスで後ろの映像が分かる、バックミラーみたいな使い方ができれば良いかもしれません。
自転車用のサイドミラーがありますが、見た目の問題で、装着に抵抗があります。
・・・スマートグラスも、まあ、装着に抵抗があるのですが。
いろいろと思いつきます。
次回は、Webカメラをラジコンに搭載し、スマートグラスで映像を見てみます。