
自然言語の評価基準「BERTScore」を使って、類似度の高い文章をスコア順に並べてみます。
この記事について
自然言語処理について基礎知識すら無い人(私)が、とにかく試して、自然言語処理とはどんなものか、イメージを掴むための内容です。
環境構築
Python 3.6以上の環境が必要です。
コマンドプロント(Windows)やターミナル(Mac)で下記を入力して、BERTScoreをインストールします。
|
1 |
pip install bert-score |
エラーが出ないことを祈ります。
Windows、Mac共に、私の環境では問題なくインストールできました。
テスト用の文章
今回は簡単なテストで、4つの文章を用意します。test.txtという名前で、任意の場所に保存してください。
|
1 2 3 4 |
吾輩は猫である 未来の世界の猫である 猫型のロボットである 眼鏡をかけた黄色い服の少年 |
4つの文章を他3つの文章と比べ、類似度のスコアを出します。
Pythonコード
「BERTScoreで文章の類似性を測定してみた」のコードを大部分参考にさせていただきました。しっかり学びたい場合は、このサイトの閲覧をお勧めします。
早く試したい場合は、下記Pythonコードをtest.pyという名前で保存してください。test.pyは、さきほどのtest.txtと同じ階層に格納します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from bert_score import score def calc_bert_score(cands, refs): Precision, Recall, F1 = score(cands, refs, lang="ja", verbose=True) return F1.numpy().tolist() #F1のみ返す if __name__ == "__main__": with open("test.txt") as f: list = [line.strip() for line in f] result = [] for index, item in enumerate(list): cands = [] for item in list: cands.append(list[index]) #総当たり用配列 F1 = calc_bert_score(cands, list) data = [] for i, item in enumerate(F1): data.append([item, i]) del data[index] data.sort(reverse=True) result.append(data) print(data) for i, item in enumerate(result): n = 0 print(list[i]) for score in item: print(" " + str(score[0]) + " : " + list[score[1]]) |
BERTScoreでは、Precision(適合率), Recall(再現率), F1(適合率と再現率の調和平均)を取得できるようです。
とりあえずF1で類似度を評価することにしました。
出力結果
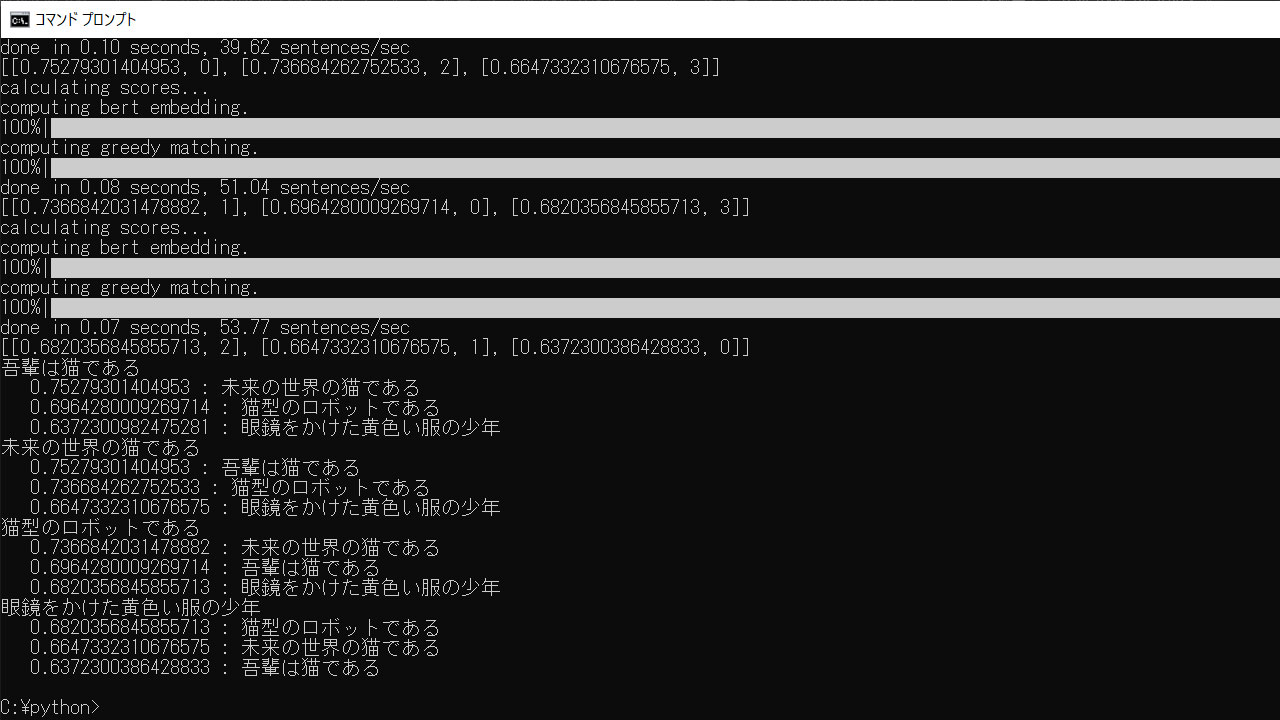
コマンドプロントなどで「python test.py」を実行すると、文章の類似度スコアが算出されます。
初回実行時のみ時間がかかります。1GB近くある学習済みモデルをダウンロードしているようでした。
しばらく待つと、各文章に対し、類似度の高い順にスコアと文章が掲載されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
吾輩は猫である 0.75279301404953 : 未来の世界の猫である 0.6964280009269714 : 猫型のロボットである 0.6372300982475281 : 眼鏡をかけた黄色い服の少年 未来の世界の猫である 0.75279301404953 : 吾輩は猫である 0.736684262752533 : 猫型のロボットである 0.6647332310676575 : 眼鏡をかけた黄色い服の少年 猫型のロボットである 0.7366842031478882 : 未来の世界の猫である 0.6964280009269714 : 吾輩は猫である 0.6820356845855713 : 眼鏡をかけた黄色い服の少年 眼鏡をかけた黄色い服の少年 0.6820356845855713 : 猫型のロボットである 0.6647332310676575 : 未来の世界の猫である 0.6372300386428833 : 吾輩は猫である |
結果としては納得いくスコアです。
「吾輩は猫である」であれば、「未来の世界の猫である」が類似しており、「猫型のロボットである」は少し違い、「眼鏡をかけた黄色い服の少年」は全く違います。
ただ、今回の文章サンプルだと、BERTのすごさを引き出せていない気もします。単純な文章で比較したので、昔からある自然言語処理でも結果が変わらないかもしれません。
まずは結果が見られたことに感謝
自然言語処理を使いこなそうと思うと、まだまだ学習と経験の積み重ねが必要だと感じます。しかし、知識がほぼ無い状況でも、BERTScoreとその使い方の情報があったおかげで、自然言語処理のイメージは掴むことができました。