

OpenCVの勉強をしていたら、となりで子供が黄色いボールで遊んでいました。ちょうど良い題材なので、黄色いボールを数える画像認識プログラムを作ります。
黄色のボールだけをカウントする

黄色いボールを取るたびに、画像左下の数字が減っていきます。
赤いミニトマトが減っても数字は変わらず、黄色いボールだけを認識します。
色だけのボール検出は難しい

黄色を抽出するだけなら簡単です。
ボールが重なっていない状態なら、ボールの数を検出することも、比較的簡単です。
しかし、2つのボールが重なっている場合、それを2つのボールと認識させるのは、難易度が高めかもしれません。
機械学習を取り入れることになりそうです。
大ざっぱにでも数えたい
低いコストで、大ざっぱにボールを数えられないでしょうか?
黄色の面積を計算すれば、ボールの概数は出せるかと思います。
元の映像だと、奥に行くほどボールの面積が小さくなるため、まずは射影変換で調整します。
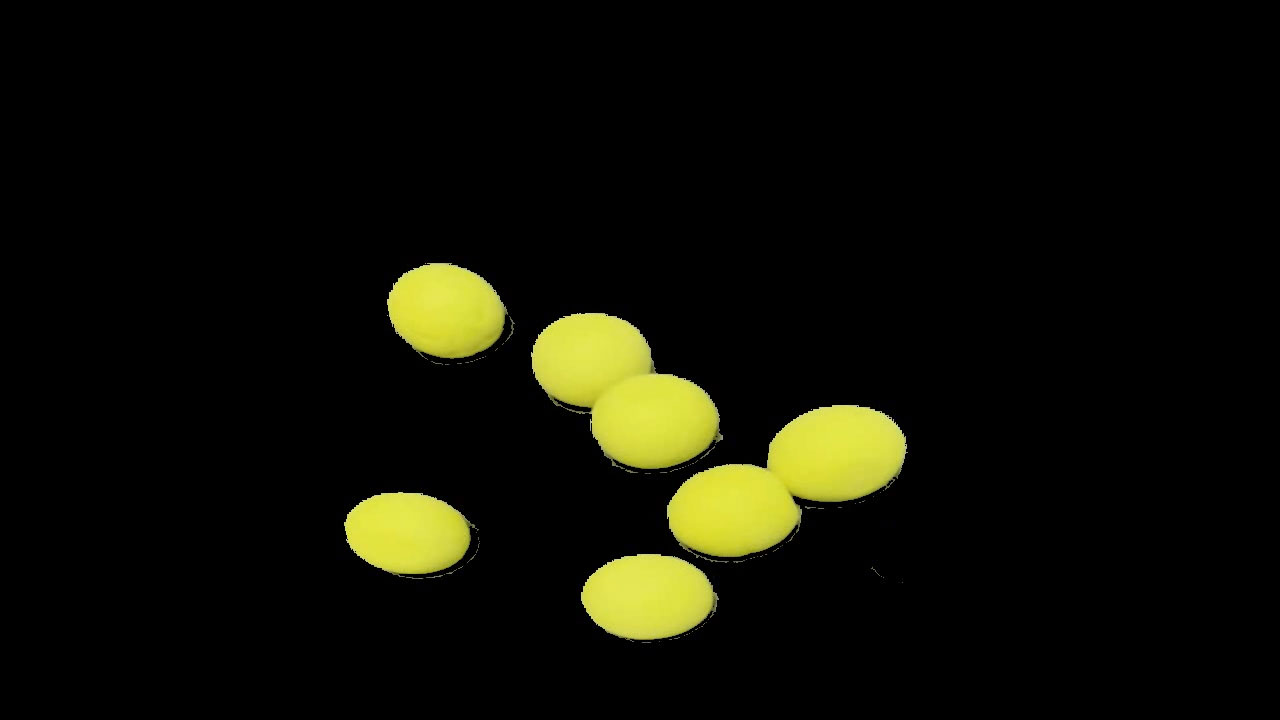
射影変換が下手で、ボールが横に潰れてしまいましたが・・・面積がだいたいそろった気がします。
これで黄色の面積を、1つ当たりのボール面積で割れば、ボールの数をカウントできます。
ボールの数が分かる1フレームを使ってマスクを生成し、cv2.countNonZero(mask) / ボールの数で、1つ当たりボール面積は計算できます。
今回の映像だと、1つのボールの面積は約9,200pxでした。
黄色ボールの概数を数えるコード
色の抽出やマスク生成は前回までのコードを使いました。
射影変換はOpenCV-Pythonチュートリアルを参考にしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import cv2 import numpy as np cap = cv2.VideoCapture('ball03.mp4') # 任意の動画 while(1): _, frame = cap.read() frameOrig = frame #ボール1つのサイズ ballSize = 9200 # 射影変換 rows, cols, ch = frame.shape pts1 = np.float32([[0, 0], [1280, 0], [0, 720], [1280, 720]]) pts2 = np.float32([[0, 0], [1280, 0], [0, 720], [1280, 720]]) M = cv2.getPerspectiveTransform(pts1, pts2) dst = cv2.warpPerspective(frame, M, (1280, 720)) frame = dst #マスク画像取得 def getMask(l, u): # HSVに変換 hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) lower = np.array(l) upper = np.array(u) if lower[0] >= 0: mask = cv2.inRange(hsv, lower, upper) else: #赤用(彩度、明度判定は簡略化) h = hsv[:, :, 0] s = hsv[:, :, 1] mask = np.zeros(h.shape, dtype=np.uint8) mask[((h < lower[0]*-1) | (h > upper[0])) & (s > lower[1])] = 255 #ボールの面積計算 ballPixels = cv2.countNonZero(mask) ballNum = str(round(ballPixels / ballSize)) return cv2.putText(frameOrig, ballNum, (100, 650), cv2.FONT_HERSHEY_SIMPLEX, 8.0, (255, 255, 255), thickness=10) # 黄色マスク num_frame = getMask([30,100,100], [40,255,255]) # 再生 cv2.imshow('video',num_frame) k = cv2.waitKey(25) & 0xFF #Q で終了 if k == ord('q'): break cv2.destroyAllWindows() |
動作の参考に、冒頭の画像を再掲載します。
今回はボールでしたが、色が識別できれば、形状は何でもOKです。
色だけで概数を簡単に調べたいときのサンプルでした。
勉強の参考になるなと思い拝見させていただきました
気になったところがありまして,この下記のコードはどのような処理分からなかったため教えてほしいです.
mask[((h upper[0])) & (s > lower[1])] = 255
あと個人的に重なっている部分を作ってみました
色認識がまだわかっていないため処理はしていません
#検出する画像の読み込み
frame = cv2.imread(‘random_clr.png’)#’Inkedcolor_circyle1_LI.jpg’)
#1チャンネル(白黒画像に変換)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#Cannyにてエッジ検出処理(やらなくてもよい)
canny_gray = cv2.Canny(gray,100,200)
#houghで使う画像の指定、後で変えたりする際に変数してしておくと楽。
cimg = canny_gray
j = 0
#hough関数
circles = cv2.HoughCircles(cimg,cv2.HOUGH_GRADIENT,1,20,param1=120,param2=20,minRadius=10,maxRadius=30)
# param1 ; canny()エッジ検出機に渡される2つの閾値のうち、大きいほうの閾値0
# param2 ; 円の中心を検出する際の投票数の閾値、小さくなるほど、より誤検出が起こる可能性がある。
# minRadius ; 検出する円の最小値
# maxRadius ; 検出する円の最大値
#検出された際に動くようにする。
if circles is not None and len(circles) > 0:
#型をfloat32からunit16に変更:整数のタイプになるので、後々トラブルが減る。
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# 外側の円を描く
cv2.circle(frame,(i[0],i[1]),i[2],(0,255,0),2)
# 中心の円を描く
cv2.circle(frame,(i[0],i[1]),2,(0,0,255),2)
# 円の数を数える
j = j + 1
font = cv2.FONT_HERSHEY_DUPLEX
#円の合計数を表示
cv2.putText(frame, “sum{}”.format(j), (5, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 1)
cv2.putText(frame, “cnt{}”.format(j), (int(i[0]), int(i[1])), font, 0.8, (0,255,255))
file_name = “sample.txt”
with open(file_name, encoding=”cp932″) as f:
data_lines = f.read()
# 同じファイル名で保存
with open(file_name, mode=”w”, encoding=”cp932″) as f:
f.write(format(j))
#結果画像の表示
cv2.imshow(”,frame)
#結果の書き込み
cv2.imwrite(‘random_clr1.png’,frame)
keiki様。重なっている部分のコードをありがとうございます!
ご質問いただいた部分の処理については、下記URLの「赤を識別する問題」に記載しています。
https://temari.co.jp/blog/2017/11/16/opencv-6/
今回は黄色だったため、質問いただいた部分のコードは使っていません。
mask = cv2.inRange(hsv, lower, upper)で、色の範囲を指定しています。
ただ、赤色の場合は、「h(色相)が0~10(橙寄りの赤)または170~180(紫寄りの赤)」というような分断された数字になってしまい、処理できません。
そのため、lower[0](色相の最小範囲)に負の値を入れた場合は、赤用の別の処理となるようにしました。
mask[((h < lower[0]*-1) | (h > upper[0])) & (s > lower[1])] = 255lower[0]が-10、upper[0]が170なら、色相が10より小さい、または170より大きい場合にマスクをする処理となります。
また、s(彩度)が高くないと赤に見えないため、最低彩度のlower[1]も条件に入れています。
・・・もっと良い方法があるかもしれません。